


Next: About this document ...
Traitement automatique du renommage de gène en biologie
Julien Jourde - MIG, INRA
Contexte
Le renommage, qui est un cas particulier de création de synonymie, est un problème qui touche de nombreux domaines (par exemple le renommage des astres ou des objets en astronomie, des gènes ou des protéines en biologies, etc). La reconnaissance automatique de ces relations entre entités nommées dans les documents, par des outils de traitement automatique du langage (TAL), est donc un enjeu important (D. Weissenbacher, 2004).
L'équipe Bibliome
(unité MIG - INRA) développe de nombreuses applications documentaires en biologie qui nécessitent l'identification avec précision, de noms de gènes et protéines, voir par exemple la base CoCitation
qui permet de rechercher des co-citations de gènes et de protéines dans les reférences PubMed, notamment celles relatives à la bactérie Bacillus subtilis. Pour maintenir cette base, les références sont régulièrement réannotées à l'aide de la chaine d'annotation AlvisNLP
et des ressources les plus récentes relatives aux organismes traités, entre autres, un dictionnaire à jour des noms de gènes et de protéines de B. subtilis et leurs synonymes.
Or, la synonymie est particulièrement riche chez cette espèce en raison d'une politique globale de renommage (bien que souvent le fait d'initiatives individuelles) :
Le renommage chez la bactérie modèle Bacillus subtilis
- Avant les années 90 : historiquement, les laboratoires travaillant sur des gènes les nommaient en fonction des phénotypes observés. Dans certains cas, un même gène était étudié par différents laboratoires observant des phénotypes différents, par exemple "rpsL" et "strA" ;
- Dans les années 90 : de nombreux gènes sont renommés à l'identique de leurs orthologues chez la bactérie Escherichia coli, par exemple "div+" devenant "secA". Apparition de nombreux noms composés de 3 minuscules (gène "xxx");
- 1995 : la publication du génome séquencé de B. subtilis incite la communauté à adopter les standards en vigueur pour le nommage des gènes d'E. coli. Apparition de noms composés de 3 minuscules et d'une majuscule (gène "xxxZ") et attribution automatique de noms aux gènes inconnus, la première lettre étant toujours un "y" (gène "yxxZ") ;
- Depuis 1995 : les renommages se poursuivent, principalement pour les gènes inconnus venant à être étudiés.
Nomenclatures
Pour rendre compte exhaustivement de la synonymie, l'annotation des références de la base CoCitation doit prendre en compte l'ensemble des informations contenues dans les 7 nomenclatures principales de B. subtilis :
- BSORF, la base maintenue par GenomeNet ;
- La Carte Génétique de B. subtilis ;
- Une base interne conçue par Anne Goeltzer et Elodie Marchadier (EA_list dans la suite) basée sur des informations bibliographiques ;
- Genome Reviews
maintenue par l'EBI ;
- GenBank
maintenue par le NCBI ;
- GenoList
(anciennement SubtiList) maintenue par l'Institut Pasteur ;
- SwissProt + TrEMBL
maintenue par le SIB et l'EBI.
La comparaison des nomenclatures révèle de graves incohérences entre les différentes bases ayant pour origines diverses causes :
- des mises à jour non concertées des bases : les contenus sont plus ou moins complets ;
- des politiques de gestion de la synonymie différentes : les gènes dits canoniques et leurs synonymes varient d'une base à l'autre ;
- des politiques de renommage initiées par les bases elles-mêmes : sur la base de comparaisons automatiques de familles de gènes entre différentes espèces par exemple, ...
Ajoutons à cela le fait qu'une partie de l'information est contenue dans les textes scientifiques et n'est répertoriée dans aucune base. Il apparait alors difficile d'établir un dictionnaire sûr et complet.
Compléter les nomenclatures et les comparer à la bibliographie
Dans l'objectif de maintenir une nomenclature aussi exhaustive que possible, mais conservant la trace de l'origine des noms, nous développons deux axes visant à :
- reconnaitre et à extraire automatiquement les relations de renommage dans les textes traitant de B. subtilis ;
- comparer les bases entre elles afin d'établir, dans un premier temps, une typologie des incohérences puis développer des outils permettant aux utilisateurs de sélectionner les synonymes pertinents à utiliser pour une recherche documentaire.
L'extraction automatique de relation de renommage
Il existe de nombreuses formes de renommage des gènes et protéines chez Bacillus subtilis :
- Forme la plus simple et la plus fréquente : "Three promoters direct transcription of the sigA (rpoD) operon in Bacillus subtilis." (PMID:3127379) ;
- Différentes déclinaisons de le forme simple : "The phoA gene (formerly called phoAIV) and the phoB gene (formerly called phoAIII) products have both [...]." (PMID:8113174) ; "[...] the presence of a functional comL (or srfA) transcription unit." (PMID:8196543) ; ...
- Renommage d'un nom en plusieurs noms indépendants : "The designation citF will be omitted, and the citF locus will be divided into three genes: sdhA, sdhB, and sdhC." (PMID:6811547) ;
- Renommage très étendu : "The nucleotide (nt) sequence of 13.6 kb of the outG locus of Bacillus subtilis, which maps at approximately 155 degrees between the genetic markers nrdA and polC, was determined. One putative coding sequence was identified corresponding to a large polypeptide of 4427 amino acids (aa). Structural organization at the nt and aa sequence level and extensive similarities of the deduced product, especially to EryA, suggest that the locus is potentially responsible for the synthesis of a polyketide molecule. The locus has been renamed pksX." (PMID:8344529) ;
Par patrons manuels
Un premier outil de reconnaissance des renommages est basé sur des patrons manuels définis à l'aide d'un corpus de 192 résumés MedLine, bacsuRename-192. Le corpus bacsuRename-192
a été sélectionné par recherche de co-citations de noms de gènes. Les couples sont formés de noms canoniques de gènes associés à chacun de leurs synonymes respectifs tels que obtenus par la fusion des nomenclatures EA_list et BSORF.
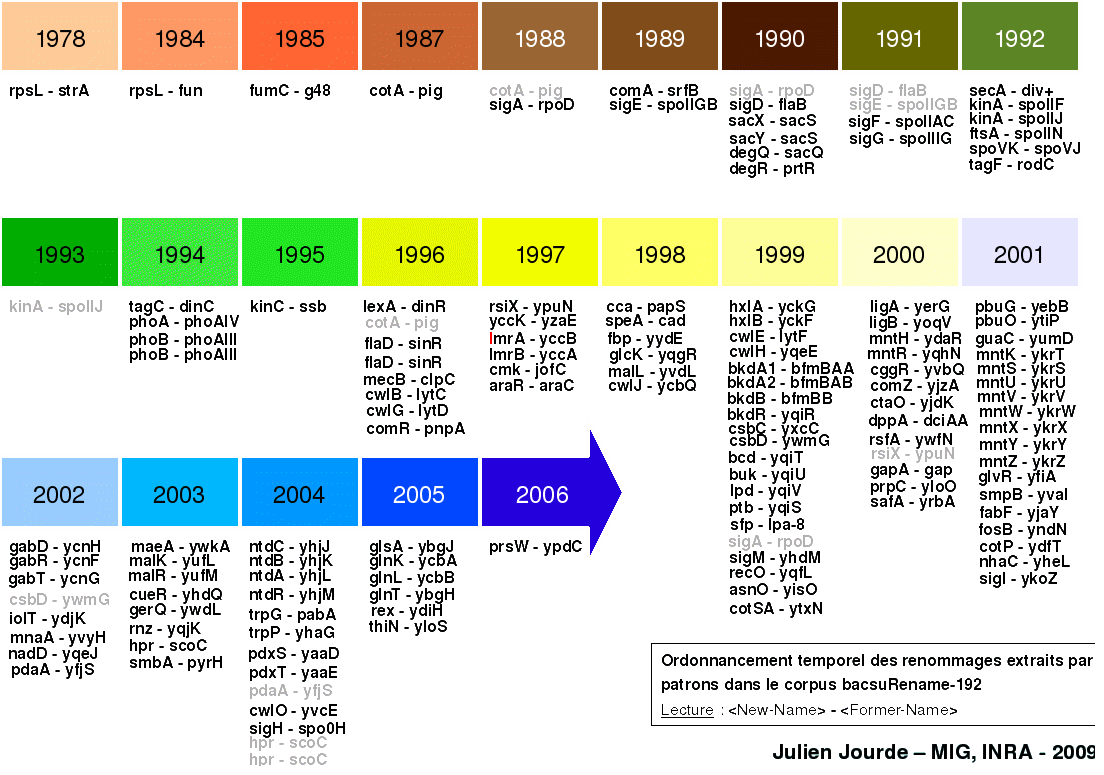
Le Rappel et la Précision de ces patrons ont été mesurés sur le corpus annoté à la main : Rappel = 65,77% et Précision = 100%. Les résultats de l'extraction ont permis un ordonnancement temporel des renommages : frise temporelle des renommages
Les formulations simples sont facilement reconnaissables avec une grande précision. Les formes plus complexes (énumérations, ...) ou dépassant les frontières de phrases sont plus difficiles à capter. Le corpus d'entrainement doit être étendu pour obtenir davantage de formes étendues, et de façon suffisante afin de tester des techniques de reconnaissance par apprentissage supervisé à partir de corpus annoté.
Par apprentissage supervisé
Annotation de corpus
La nomenclature utilisée pour sélectionner le corpus étendu appelée Gold, est obtenue par la fusion des sept bases.
Le nouveau corpus de 1 843 références PubMed, bacsuRename-1843, est obtenu par double sélection :
- recherche de co-citations. Les couples employés sont les noms canoniques du nouveau Gold associés à chacun de leurs synonymes respectifs, ainsi que les couples de synonymes eux-mêmes ;
- recherche de mots-clés liés au renommage ("designated", "renamed", ...).
L'annotation manuelle est réalisée à l'aide de l'éditeur d'annotation XML Cadixe
après la conversion des fichiers au format cadixe. Cadixe
est un outil d'annotation issu d'une collaboration entre MIG et l'IMAG. Le fichier de logs
associé indique quels couples ou termes ont été détectés lors de la sélection du corpus.
La dtd
(Document Type Definition, fichier décrivant la structure des annotations utilisables dans Cadixe), la css
(feuille de style) et les guidelines
associées en rendent compte.
Une première phase d'annotation manuelle par TranSys
Les chercheurs du projet TranSys ont contribué à mettre le cadre de l'annotation au point.
La session de travail TranSys
:
- Présentations des tâches d'annotation des renommages et de résolution de conflits entre les nomenclatures ;
- Annotations par les étudiants ;
- Analyse des résultats et modification de la dtd
afin de faciliter l'annotation et l'apport d'informations pour l'utilisateur final.
Une deuxième phase d'annotation manuelle dans Quaero
L'annotation du corpus bacsuRename-1843
est en cours de finalisation avec l'INIST;
Cadre de l'apprentissage
- Estimation du Rappel et de la Précision des patrons sur bacsuRename-1843. Typologie des faux positifs et faux négatifs ;
- Apprentissage en trois temps grâce à la modification et l'utilisation de la chaine AlvisNLP/ML ;
- Filtrage des phrases positives (mentionnant un renommage) ;
- Identification des rôles des gènes et protéines (source ou cible) ;
- Extraction des relations de renommage.
Ce travail est partiellement financé par le projet Oséo Quaero.
Next: About this document ...
julien
2010-02-22
{kind=link}