Les basiques autour des NGS
Module 5 - DUBii 2018
Olivier Rué & Olivier Kirsh
Objectifs de ce cours
- Connaître les ressources bioinformatiques en ligne pour traiter des données NGS
- Savoir récupérer en local ce type de ressources
- Découvrir les principaux formats de fichiers
Jeu de données
Bacterial regulons in Escherichia coli with ChIP-seq and RNA-seq
Myers KS, Park DM, Beauchene NA, Kiley PJ. Defining bacterial regulons using ChIP-seq. Methods. 2015 Sep 15;86:80-8. doi: 10.1016/j.ymeth.2015.05.022. Epub 2015 May 29. Review.
PubMed PMID: 26032817
Environnement de travail
Pour ce cours, vous travaillerez sur la machine locale qui vous est mise à disposition
Vous aurez besoin du terminal et d'un navigateur web

Introduction
Les essentiels d'un pipeline d'analyse de données NGS
- Ressources (données issues du séquençage, génome de référence, annotations, base de données...)
- Centralisées
- Pas toujours pour les organismes non modèles
- Une liste exhaustive est disponible entre autres ici
- Outils
- Certains incontournables au NGS
- Dépendants de la thématique et/ou de l'analyse souhaitée
- Beaucoup sont recensés ici : labworm.com
- Puissance de calcul (mémoire/coeurs) !
- clusters de calculs ouverts à la communauté [cf cours Unix 2]
- Des connaissances en Unix (au moins)
Les principales ressources en ligne
Vous aurez forcément besoin d'utiliser des ressources produites et expertisées par d'autres. Il existe une multitude de sites recensant des ressources bioinformatiques. Les incontournables et les plus généralistes sont :
- Nucleotide Sequence Databases :
- Genome databases :
Une classification plus exhaustive (séquences protéiques, domaines protéiques, structures protéiques 3D, voies métaboliques...) est disponible entre autres ici
NCBI
Le NCBI héberge et met en relation de nombreuses bases de données :
- Pubmed : publications et citations
- SRA : Sequence Read Archive (données de sortie de séquençage ou alignées vs référence)
- Genbank : collection de séquences ADN annotées publiques
- RefSeq : collection de séquences de génomes, de transcripts et de protéines, non redondantes
- dbSNP : collection de variants, microsatellites... humains
- GEO : collection de données liées à l'expression des gènes
- ...
Tout (ou presque) est interconnecté
ENA
L'ENA est l'équivalent européen du NCBI, hébergé à l'EMBL-EBI :
- Données de séquençage
- Assemblages de génomes annotés
- Annotations fonctionnelles de génomes
- ...
Les Accession Numbers
Les ressources sont décrites par un Accession Number. C'est leur numéro unique qui permet de les retrouver.
La nomenclature change en fonction des ressources (NCBI, ENA...) mais le préfixe reste fixe :
- 'DR' pour DDBJ Sequence Read Archive (DRA)
- 'EGA' pour European Genome-phenome Archive (EGA)
- 'ER' pour ENA Read
- 'SR' pour NCBI Sequence Read Archive (SRA)
Par contre un même Accession Number peut être stocké sur plusieurs ressources !
Les données issues du séquençage
Les principales ressources publiques
La grande majorité des données brutes sont stockées soit au NCBI (Etats-Unis - NIH), soit à l'EBI (Angleterre - EMBL).
Depuis quelques temps, les reviewers exigent que vos données soient déposées et accessibles à la communauté.

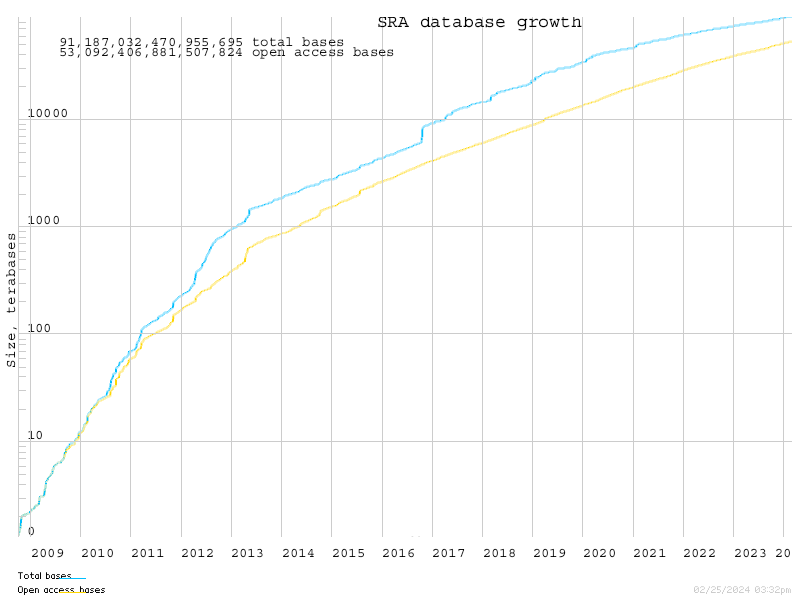
Exercice n°1 : Retrouver où ont été déposées les données de séquençage de la publication
Une section est souvent dédiée à la mise à disposition des données en fin d'article
- Dans quelle base de données ont été déposées les données brutes ?
- Quel est leur numéro d'accession ?
- Allez sur le site en question et entrez le numéro d'accession dans la barre de recherche. Combien d'échantillons sont disponibles ?
- Cliquez sur la sous-série GSE41187 (analyse Chip-Seq) puis suivez le lien vers SRA
- Combien de fichiers de séquences brutes pouvez-vous récupérer ?
- Que pouvez-vous dire sur le séquençage du 1er run ? (SRX220453)
- Pouvez-vous le télécharger via l'interface ?
- Quelle solution vous est proposée ?
Correction n°1
- Dans quelle base de données ont été déposées les données brutes ? GEO - NCBI
- Quel est leur numéro d'accession ? GSE41195
- Allez sur le site en question et entrez le numéro d'accession dans la barre de recherche. Combien d'échantillons sont disponibles ? 48
- Cliquez sur la sous-série GSE41187 (analyse Chip-Seq) puis suivez le lien vers SRA
- Combien de fichiers de séquences brutes pouvez-vous récupérer ? 9
- Que pouvez-vous dire sur le séquençage du 1er run ? (SRX220453) Chip-Seq, Illumina GAIIx, reads sinlge-end, 878,466 reads
- Pouvez-vous le télécharger via l'interface ? Non
- Quelle solution vous est proposée ? SRA Toolkit
SRA toolkit
Suite d'utilitaires permettant, en ligne de commande, de récupérer des données du NCBI. L'outil est généralement accessible sur les clusters de bioinformatique. La documentation est indispensable pour l'utiliser (au début du moins).
Les principales commandes sont :
- prefetech : pour télécharger les fichiers sra
- fastq-dump : pour télécharger les fichiers au format fastq ou fasta
Exercice n°2 : Utiliser SRA toolkit
- Affichez l'aide de la commande fastq-dump dans le terminal
- Télécharger le run SRR653522
- Affichez les dix premières lignes du fichier
- Bonus : télécharger une liste de fichiers SRR
Correction n°2 : Utiliser SRA toolkit
fastq-dump -h # Afficher l'aide
[orue@migale tmp]$ fastq-dump -h
Usage:
fastq-dump [options] [...]
fastq-dump [options]
fastq-dump SRR653522 # Télécharger le run SRR653522
head SRR653522.fastq
@SRR653522.1 ILLUMINA05:2:1:0:2016 length=35
NCGTCGACCATTTCCAGCTCGCCGCCAACCGGAAC
+SRR653522.1 ILLUMINA05:2:1:0:2016 length=35
&<9<<<<<<<<<<<<<9<<<<<<<<<2<<<<<<<<
@SRR653522.2 ILLUMINA05:2:1:0:69 length=35
NGGCTAATGGCATCTTTATGATTGTTAATAATAGA
+SRR653522.2 ILLUMINA05:2:1:0:69 length=35
&=AA=<2====<=??A=,==:=====9==.<=2=.
@SRR653522.3 ILLUMINA05:2:1:0:418 length=35
NAACGTACAAATACTGGGGTGATTTTGTTCGGATC
head SRR_accessions.txt # Il faut remplir le fichier avec les Accession Numbers trouvés sur la page du projet (SRA Run Selector)
SRR576933
SRR576934
SRR576935
SRR576936
SRR576937
SRR576938
SRR653520
SRR653521
SRR653522
cat SRR_accessions.txt | xargs fastq-dump # Télécharger une liste de SRR
Le format FASTQ
C'est le format utilisé pour stocker des fragments séquencés (lectures ou reads)
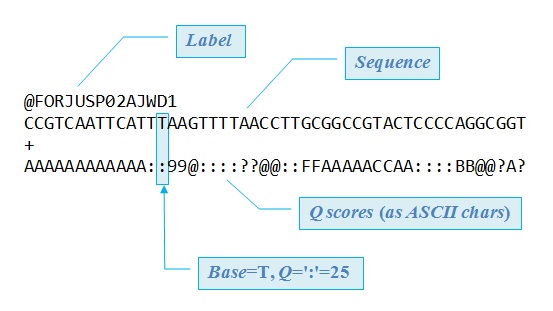
- Fichier texte (.fastq)
- 4 lignes par séquence
- Hautement compressible (.fastq.gz)
gzip file.fastq # To compress
gzip -d file.fastq.gz # To uncompress
Encodage de la qualité de la base séquencée
Un score Phred est attribué par le séquenceur à chaque base séquencée, quelle que soit la technologie utilisée. Elle représente la confiance accordée à la base.
Elle est encodée en ASCII pour tenir sur un seul caractère.
Les scores de qualité varient selon les technologies de séquençage ! Attention !
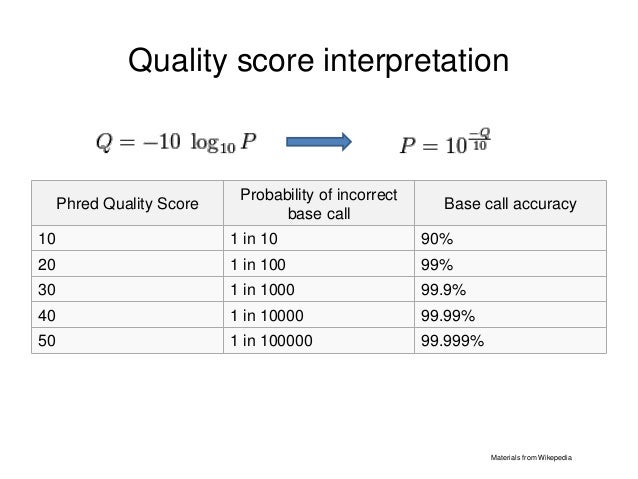

Exercice n°3 : Extraire informations du FASTQ
- Combien de séquences y a-t-il dans le fichier SRR5344684_1.fastq ?
Correction n°3 : Extraire informations du FASTQ
wc -l SRR5344684_1.fastq # Puis diviser par 4
89629572 SRR5344684_1.fastq
cat SRR5344684_1.fastq | echo $((`wc -l`/4))
22407393
Contrôle qualité des fichiers FASTQ
FastQC est la référence pour analyser la qualité des lectures au format FASTQ.
MultiQC permet de synthétiser tous les rapports en un seul rapport.
Vous aurez accès à :
- Nombre de lectures
- Taille des lectures
- Qualité moyenne de la base séquencée à chaque position
- Présence d'adaptateurs de séquençage
- GC content
- ...
fastqc file.fastq.gz # Run fastqc on one compressed FASTQ file
# Open .html in a web browser
Vous le verrez en détail lors du cours Production de données #2
Le génome de référence
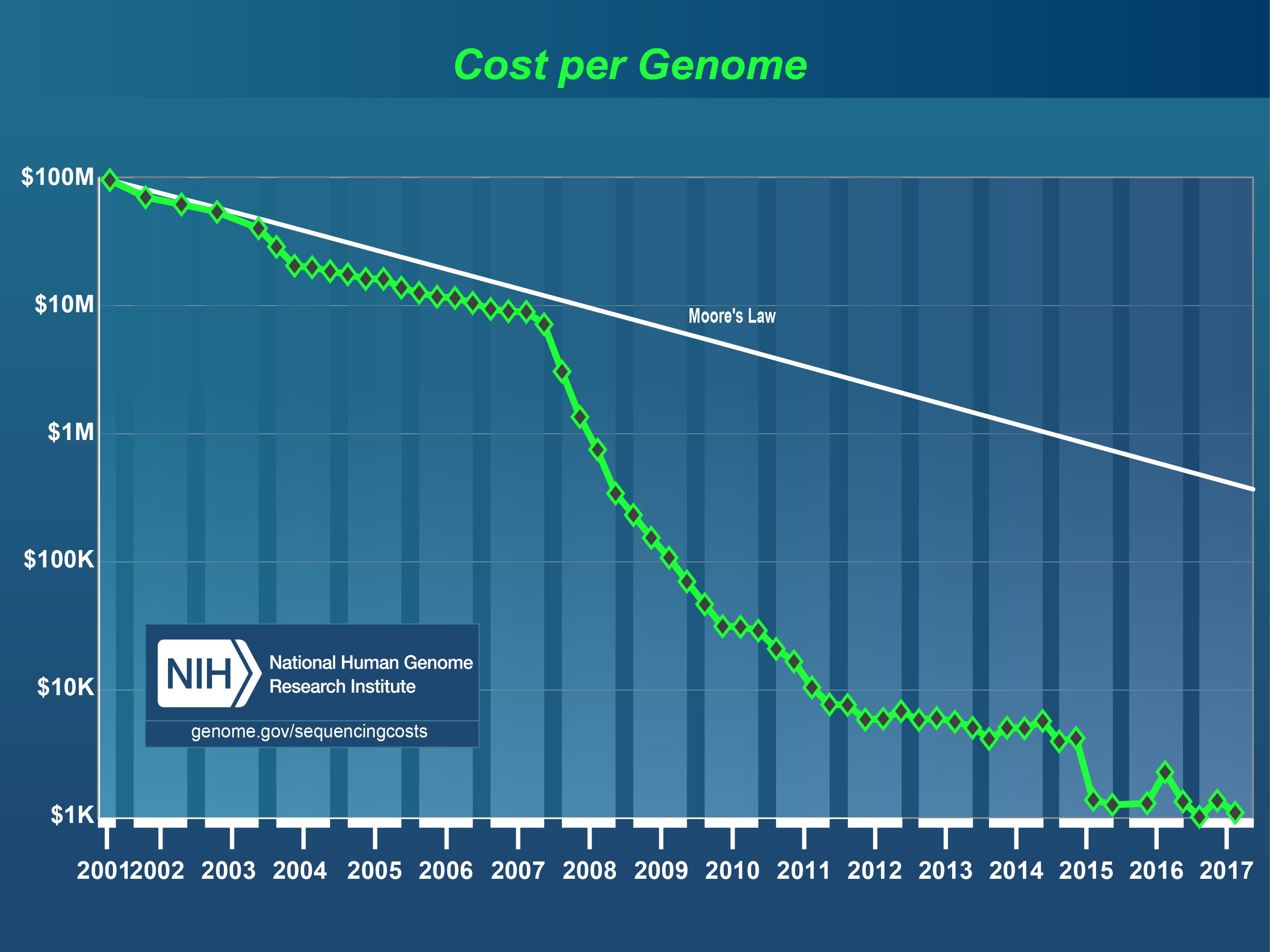
La plupart des pipelines bioinformatiques reposent sur la présence d'une référence. Soit elle existe, soit il faut en construire une.
Attention, il existe des génomes complètement séquencés et très bien annotés (les organismes modèles), d'autres sont une succession de fragments représentant une sous-partie du génome.
La croissance du nombre de génomes est exponentielle (exemple du génome humain) :
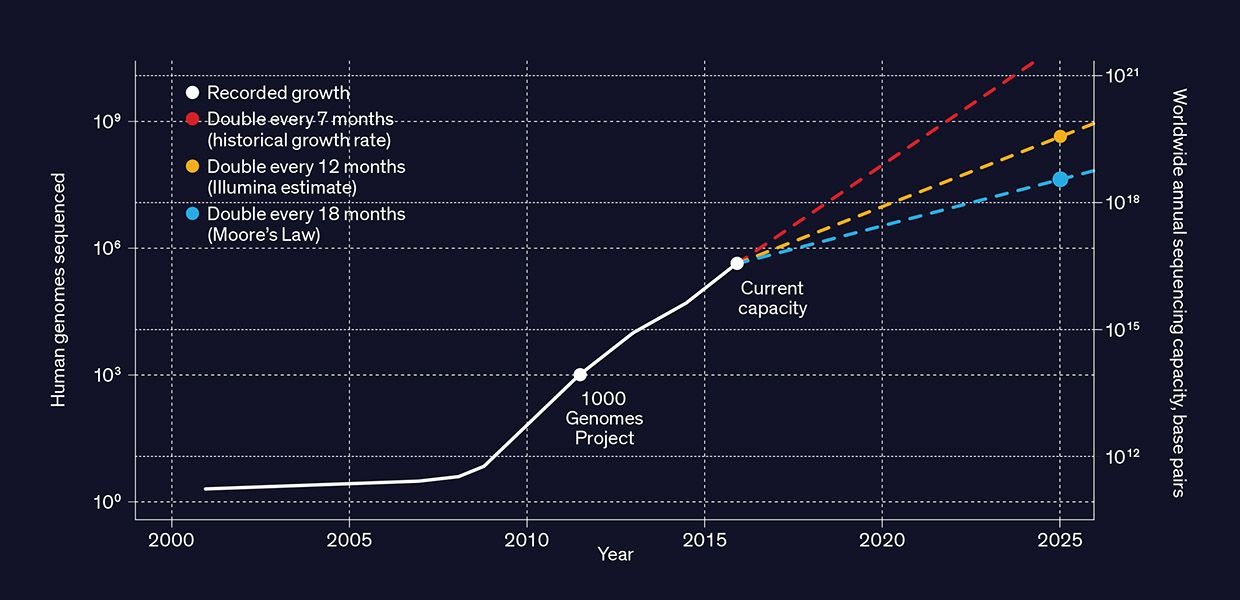
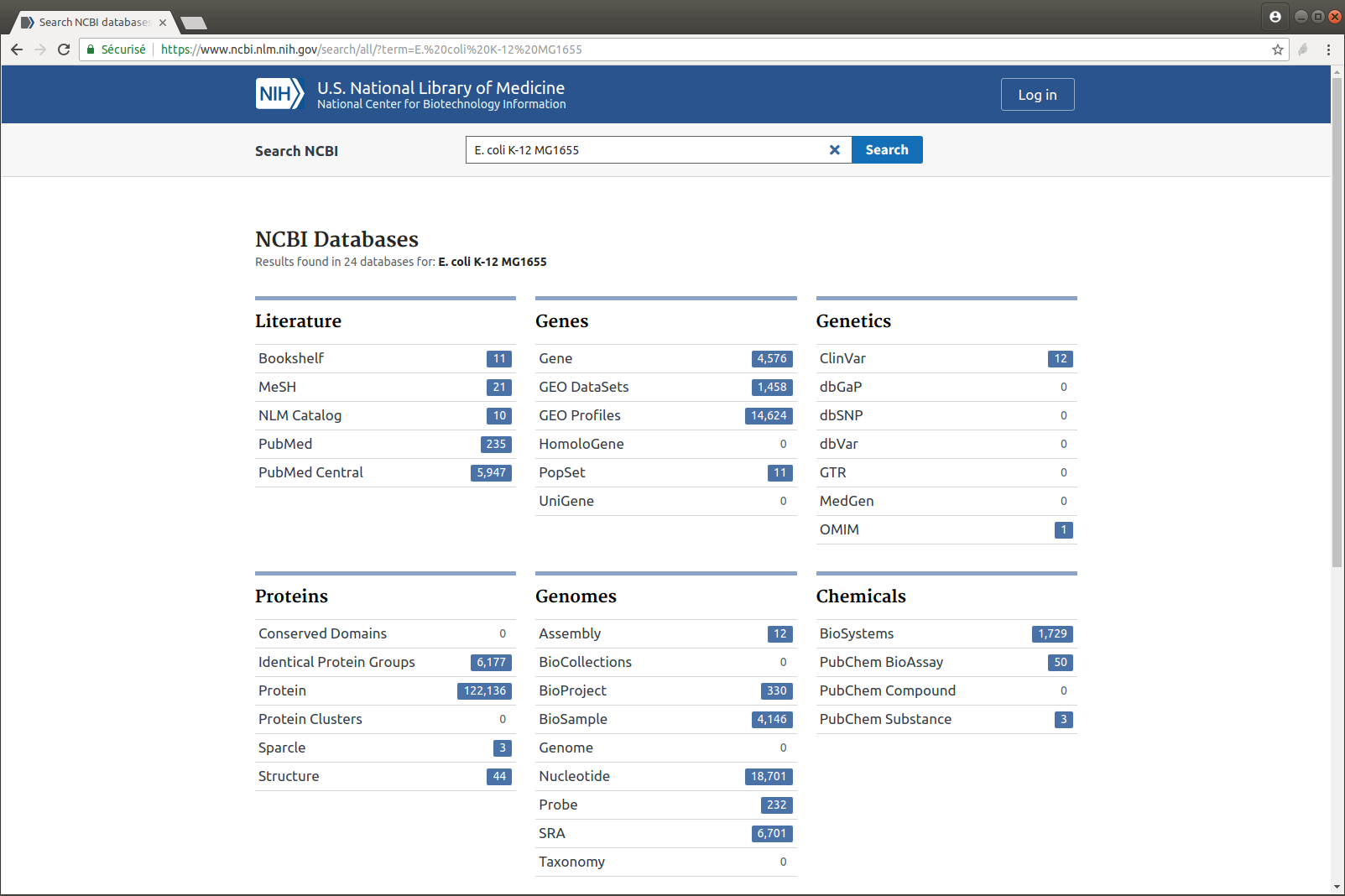
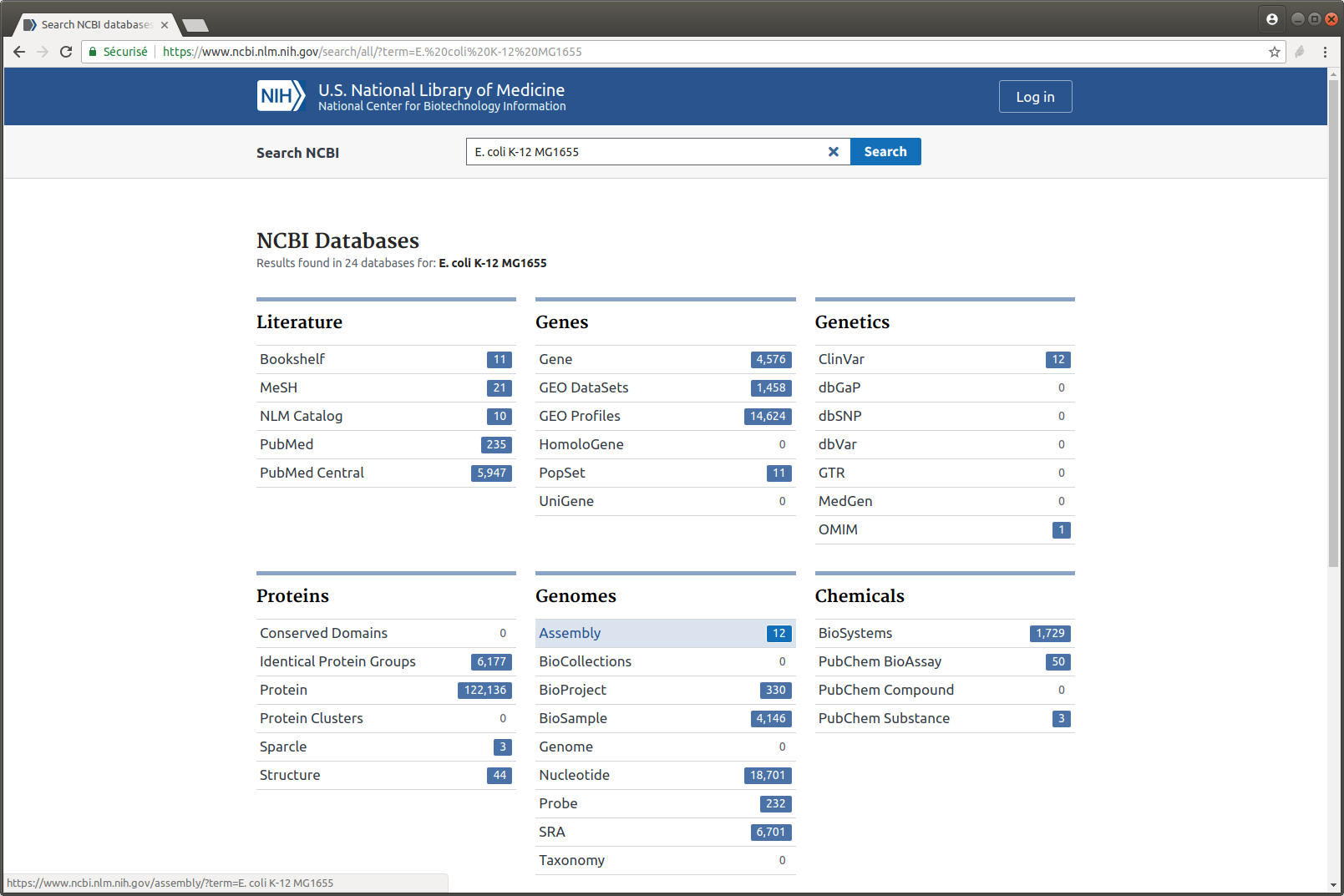
Exercice n°4 : Récupérer le génome utilisé dans la publication : E. coli K-12 MG1655
- Recherchez cette référence sur le site du NCBI
- Combien y a-t-il de versions de cet assemblage ?
- Téléchargez la dernière version mise à jour
- Affichez les dix premières lignes du fichier
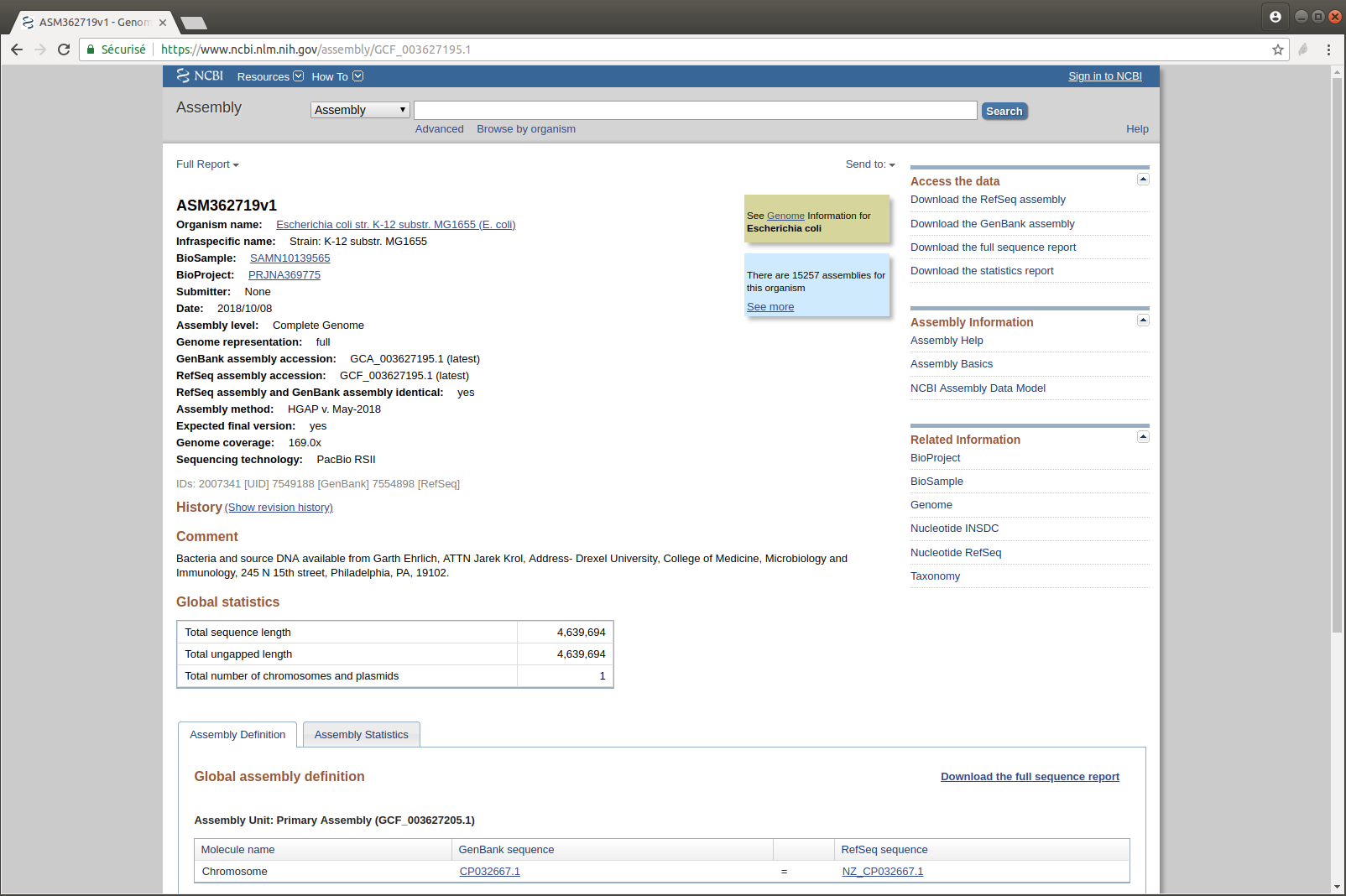
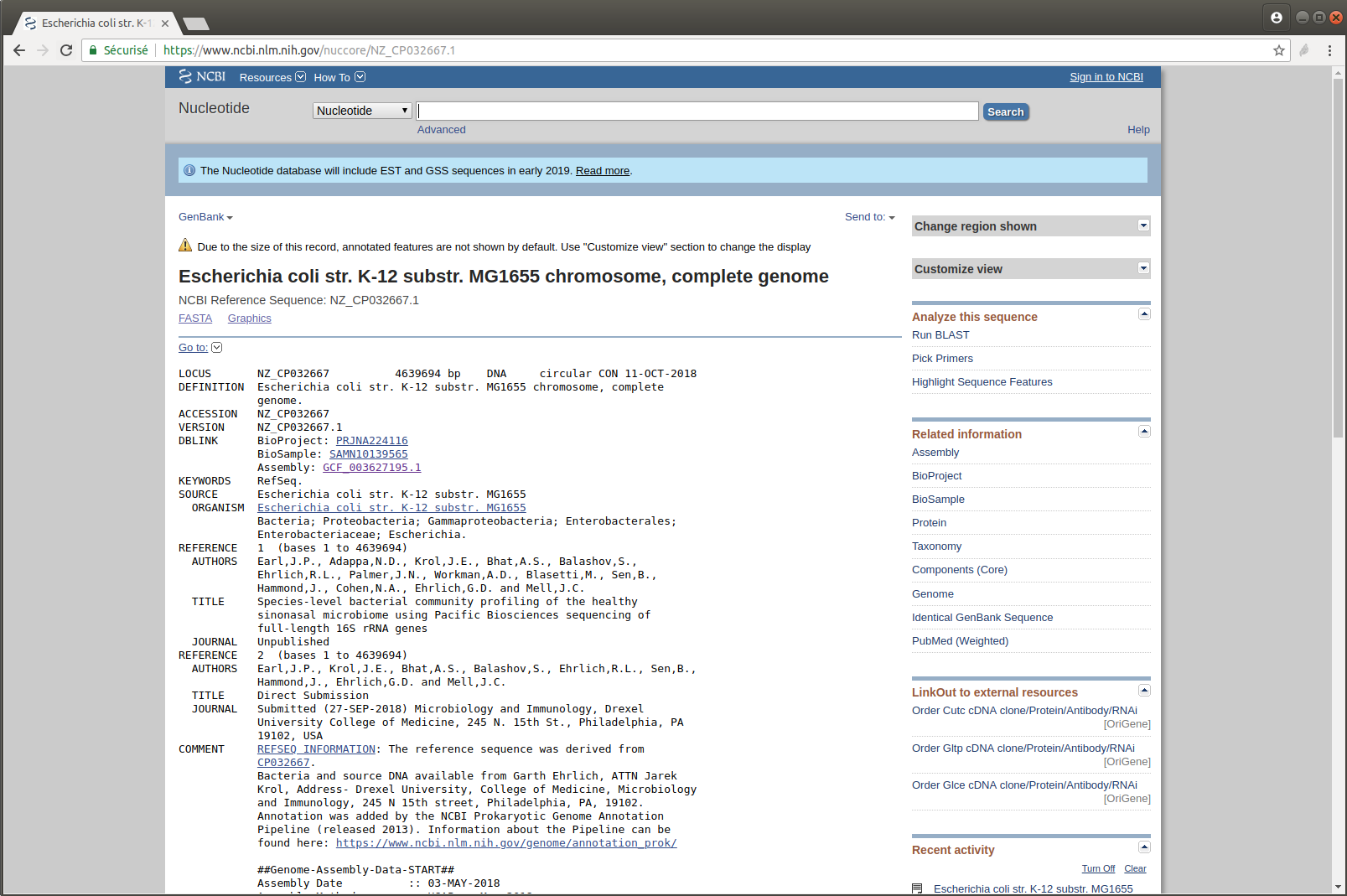
head sequence.fasta
>NZ_CP032667.1 Escherichia coli str. K-12 substr. MG1655 chromosome, complete genome
GTCCCGGCCCCGGCAGAACCGACCTATCGTTCTAACGTAAACGTCAAACACACGTTTGATAACTTCGTTG
AAGGTAAATCTAACCAACTGGCGCGCGCGGCGGCTCGCCAGGTGGCGGATAACCCTGGCGGTGCCTATAA
CCCGTTGTTCCTTTATGGCGGCACGGGTCTGGGTAAAACTCACCTGCTGCATGCGGTGGGTAACGGCATT
ATGGCGCGCAAGCCGAATGCCAAAGTGGTTTATATGCACTCCGAGCGCTTTGTTCAGGACATGGTTAAAG
CCCTGCAAAACAACGCGATCGAAGAGTTTAAACGCTACTACCGTTCCGTAGATGCACTGCTGATCGACGA
TATTCAGTTTTTTGCTAATAAAGAACGATCTCAGGAAGAGTTTTTCCACACCTTCAACGCCCTGCTGGAA
GGTAATCAACAGATCATTCTCACCTCGGATCGCTATCCGAAAGAGATCAACGGCGTTGAGGATCGTTTGA
AATCCCGCTTCGGTTGGGGACTGACTGTGGCGATCGAACCGCCAGAGCTGGAAACCCGTGTGGCGATCCT
GATGAAAAAGGCCGACGAAAACGACATTCGTTTGCCGGGCGAAGTGGCGTTCTTTATCGCCAAGCGTCTA
Le format FASTA
C'est un fichier texte contenant des informations sur une séquence (nucléique ou protéique).

Des blocs de 60 lettres sont souvent utilisés.
L'extension peut être .fa, .fasta, .fna...
Le mapping
Les algorithmes de mapping
Les algorithmes de mapping doivent s'adapter à la quantité et à la longueur des lectures issues du séquençage.
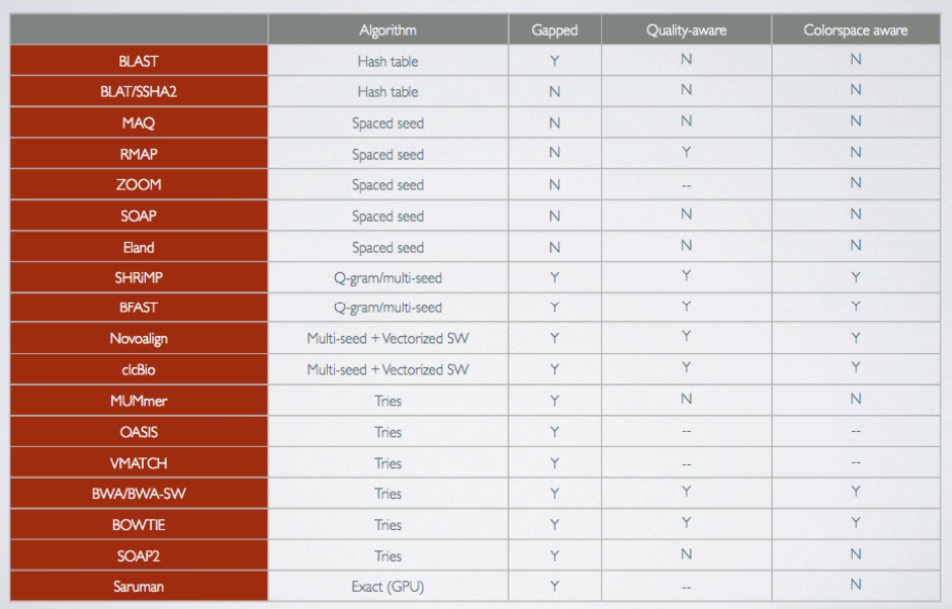

Le choix de l'outil et le paramétrage est dépendant des données (nature, longueur, quantité)
Quelques exemples parmi les plus utilisés :
Avant de mapper les reads... on nettoie
Il faut nettoyer les reads pour enlever tout ce qui n'est pas 'biologique' et de 'mauvaise qualité' :
- Enlever les adaptateurs de séquençage, les barcodes... (cutadapt...)
- Trimmer les bases de mauvaise qualité (sickle, trimmomatic...)

Avant de mapper les reads... on nettoie
Puis filtrer/nettoyer/pre-processer selon différents critères :
- Enlever les lectures contenant des bases ambigues (pas toujours supportées par les outils)
- Supprimer les lectures trop petites
- Supprimer les lectures avec une complexité trop faible
- Merger les paires chevauchantes (pear, vsearch...)
- ...
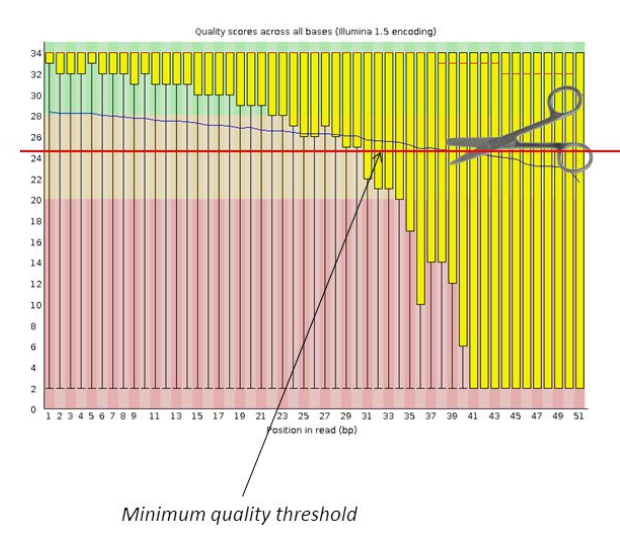
Avant de mapper les reads... on nettoie
Chaque jeu de données est différent ! Il faut mesurer les effets de chaque étape (nombre de reads perdus, taille...) en faisant des graphiques, des tableaux...
C'est l'expérience qui guidera ensuite vos choix.
Le format SAM / BAM
Le format SAM a été élaboré lors du projet des 1000 génomes humains.
Il permet de stocker toutes les informations utiles des lectures alignées sur une référence.
Tous les outils de mapping génèrent du SAM.
Hautement compressible, indexable pour un accès rapide à l'information.
Le format SAM est un fichier texte. Sa version compressée est un BAM. Sa version ultra compressée est un CRAM.
Les informations dans le SAM

Documentation : SAM flags
Les informations dans le SAM

Manipuler les formats SAM / BAM
En complément du format, la suite d'outils SAMTOOLS a été développée pour manipuler ces formats.
Fonctionnalités :
- Compression / Décompression
- Tri / Indexage
- Merge
- Statistiques
- ...
Exercice n°5 : Manipuler des fichiers SAM/BAM
- Visualiser le contenu d'un fichier BAM
- Obtenir des statistiques sur le fichier BAM
- Trier le fichier BAM
- Indexer le fichier BAM
Visualiser le contenu d'un fichier BAM
samtools view # Affiche l'aide
samtools view file.bam | less # Ne pas oublier | less
Obtenir des statistiques sur le fichier BAM
samtools flafstat # Affiche l'aide
samtools flagstat file.bam
Trier le fichier BAM
samtools sort # Affiche l'aide
samtools sort -o file.sorted.bam file.bam
Indexer le fichier BAM
samtools index # Affiche l'aide
samtools index file.sorted.bam
Les annotations du génome de référence
Le génome de référence donne uniquement des informations sur la séquence. Toutes les informations recensées ici (Sequence Ontology) (intron, exon, promoter, rRNA, CDS, centromere...) sont stockées ailleurs, dans un fichier d'annotation, qui indique leurs positions et leurs caractéristiques.
Le format GFF
Le format Gene Feature Format(GFF/ GFF2/GFF3) est un fichier texte où chaque ligne correspond à une annotation ou une feature. Les formats GFF, GFF2 et GFF3 sont légèrement différents.
La séquence peut être ajoutée en fin de GFF3

Exemple d'un GFF3
Il existe d'autres formats d'annotation, notamment Genbank, spécifique au NCBI, qui contient séquences et annotations.

Exercice n°6 : Récupérer l'annotation du génome E. coli K-12 MG1655 au NCBI
- Récupérer l'annotation du génome E. coli K-12 MG1655 au NCBI au format GFF3
- Afficher les 10 premières lignes du fichier GFF3
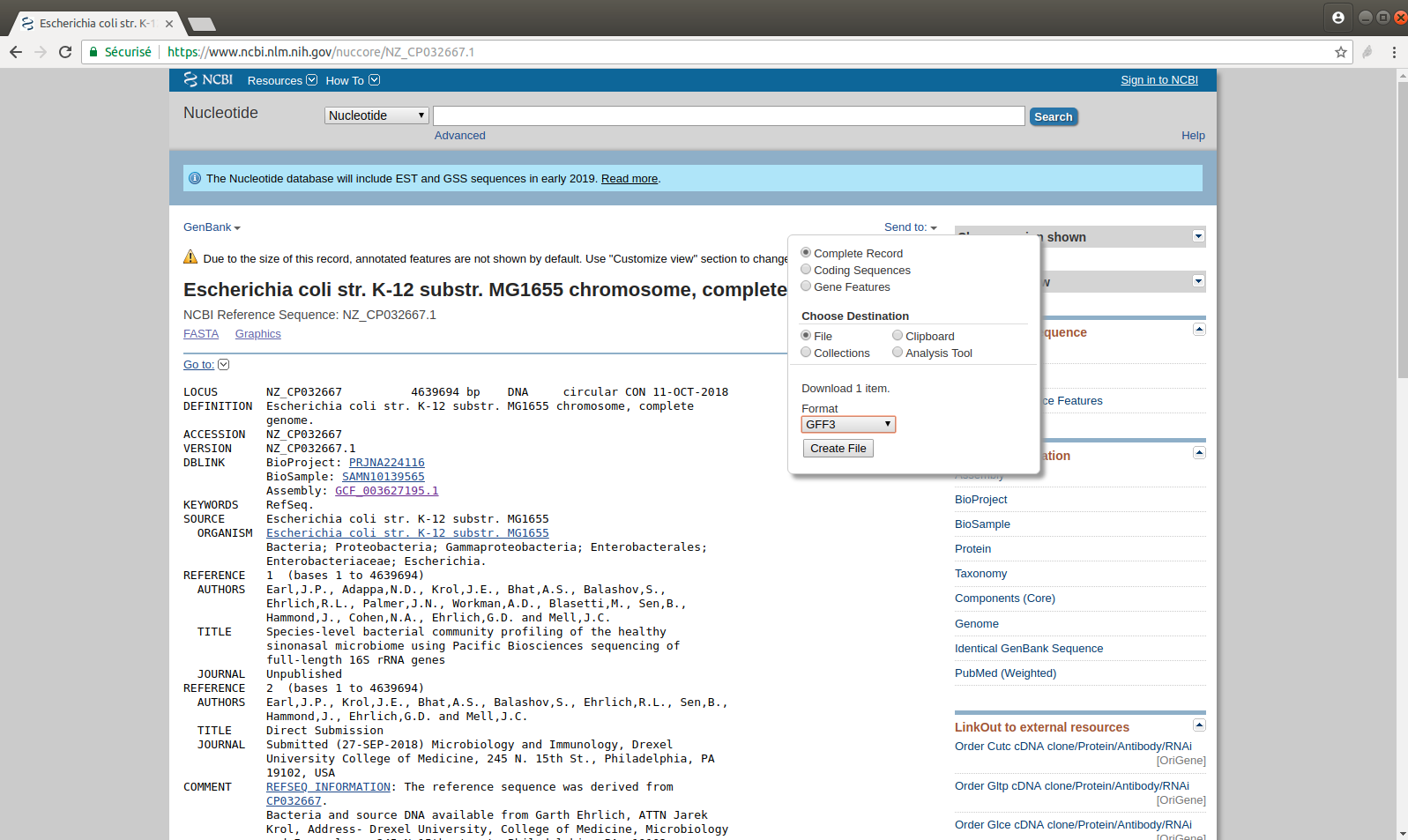
head sequence.gff3
##sequence-region NZ_CP032667.1 1 4639694
##species https://www.ncbi.nlm.nih.gov/Taxonomy/Browser/wwwtax.cgi?id=511145
NZ_CP032667.1 RefSeq region 1 4639694 . + . ID=NZ_CP032667.1:1..4639694;Dbxref=taxon:511145;Is_circular=true;Name=ANONYMOUS;collection-date=2018;country=USA: Philadelphia;gbkey=Src;genome=chromosome;lat-lon=39.95 N 75.16 W;mol_type=genomic DNA;note=obtained from culture collection;old-name=Escherichia coli K-12;strain=K-12;substrain=MG1655
NZ_CP032667.1 RefSeq gene 1052 2152 . + . ID=gene-D8B36_RS00010;Name=D8B36_RS00010;gbkey=Gene;gene_biotype=protein_coding;locus_tag=D8B36_RS00010;old_locus_tag=D8B36_00010
NZ_CP032667.1 Protein Homology CDS 1052 2152 . + 0 ID=cds-WP_000673464.1;Parent=gene-D8B36_RS00010;Dbxref=Genbank:WP_000673464.1;Name=WP_000673464.1;gbkey=CDS;inference=COORDINATES: similar to AA sequence:RefSeq:WP_006177590.1;locus_tag=D8B36_RS00010;product=DNA polymerase III subunit beta;protein_id=WP_000673464.1;transl_table=11
NZ_CP032667.1 RefSeq gene 2152 3225 . + . ID=gene-D8B36_RS00015;Name=recF;gbkey=Gene;gene=recF;gene_biotype=protein_coding;locus_tag=D8B36_RS00015;old_locus_tag=D8B36_00015
NZ_CP032667.1 Protein Homology CDS 2152 3225 . + 0 ID=cds-WP_000060112.1;Parent=gene-D8B36_RS00015;Dbxref=Genbank:WP_000060112.1;Name=WP_000060112.1;gbkey=CDS;gene=recF;inference=COORDINATES: similar to AA sequence:RefSeq:WP_005121479.1;locus_tag=D8B36_RS00015;product=DNA replication/repair protein RecF;protein_id=WP_000060112.1;transl_table=11
NZ_CP032667.1 RefSeq gene 3254 5668 . + . ID=gene-D8B36_RS00020;Name=D8B36_RS00020;gbkey=Gene;gene_biotype=protein_coding;locus_tag=D8B36_RS00020;old_locus_tag=D8B36_00020
NZ_CP032667.1 Protein Homology CDS 3254 5668 . + 0 ID=cds-WP_000072067.1;Parent=gene-D8B36_RS00020;Dbxref=Genbank:WP_000072067.1;Name=WP_000072067.1;gbkey=CDS;inference=COORDINATES: similar to AA sequence:RefSeq:NP_312661.1;locus_tag=D8B36_RS00020;product=DNA gyrase subunit B;protein_id=WP_000072067.1;transl_table=11
NZ_CP032667.1 RefSeq gene 5899 6306 . + . ID=gene-D8B36_RS00025;Name=D8B36_RS00025;gbkey=Gene;gene_biotype=protein_coding;locus_tag=D8B36_RS00025;old_locus_tag=D8B36_00025
Autres indispensables
Formats
Outils
- BEDtools pour manipuler les fichiers génomiques (intersections...)
- IGV pour visualiser ces fichiers le long d'un génome
- ...
Librairies